过去一周,堪称是黄仁勋职业生涯的高光时刻。
其所创办的英伟达市值一度突破1万亿美元,成为全球最受瞩目的AI芯片巨头。与此同时,新型“算力杀器”DGX GH200超级计算机的发布,无疑将引燃生成式AI的下一个增长点。
此刻没有人会质疑,英伟达在人工智能领域所处的领导地位。就像媒体大篇幅渲染的那样,黄仁勋现在是“秦始皇吃花椒”——赢麻了。
价格遭“哄抬”的GPU

图片来源:英伟达
“全世界都在讲中国话”这句歌词,放到英伟达身上,应当变成“全世界都在抢GPU”。
截至今年4月30日的3个月里,英伟达共实现营收71.9亿美元,数据中心业务贡献了42.8亿美元。随着生成式AI大模型不断涌现,云计算和科技公司对GPU的需求都达到了前所未有的高度。
目前这种情况还在继续。来自供应链的消息显示,英伟达在手订单已经超过10万片。包括A100/A800和H100等GPU产品不仅供不应求,采购价格也是水涨船高。
不到半年的时间,A100价格上涨近四成。若按照1万美元、1000片的起步价来计算,多出的成本少则也能达到数百万美元。而早在今年2月份,国内某大模型供应商就透露,A100的租赁价格已上涨了约50%。
尽管如此,此类GPU如今已是紧俏货。根据媒体消息,眼下,英伟达选择优先供货Google、微软等至少下单了1万~2万片的云端大客户,其他客户的交付周期已延长至6个月。相关服务器厂商预计,GPU短缺情况至少会持续到明年。
GPU加单不断,陷入全球疯抢,背后是一场关于算力的争夺战。

AI对计算能力的需求呈指数级增长;图源:TheEconomist
《智能世界2030》报告中预测,到2030年,人类将进入YB数据时代,通用算力将增长10倍、人工智能算力将增长500倍。
要知道,AI训练与推理离不开底层计算处理器的支持,算力瓶颈已成为人工智能发展的最大障碍。而生成式AI大模型又是“大算力+强算法”的产物,对算力的依赖更加突出。
ChatGPT 的缔造者OpenAI就预计,模型计算量的增长速度远超人工智能硬件算力的增长速度,甚至存在万倍差距。摩尔定律放缓,势必进一步限制人工智能的发展潜力。
因而大模型的出现必然将伴随着计算技术的发展。
借用黄仁勋在GTC 2023上说的话,“如果计算技术是以光速在进步,那么加速计算就是超光速的曲速引擎。”而人工智能应用负载对算力的强烈需求就是能量来源。近年来,越来越多的观点和实践都证明了GPU在通用加速计算领域的优势。
在GPU架构里,计算单元(ALU)占据了相当大的比重。相比CPU,GPU的浮点运算能力更强,且架构专为并行计算而设计,可兼容训练和推理,更加注重整体数据的吞吐量。同时随着可编程性不断提高,GPU在削减架构本身的图形显示部分后,可以全部投入到通用计算里。
也就是所谓的“GPGPU”,通用计算处理器。

图片来源:HEAVY.AI
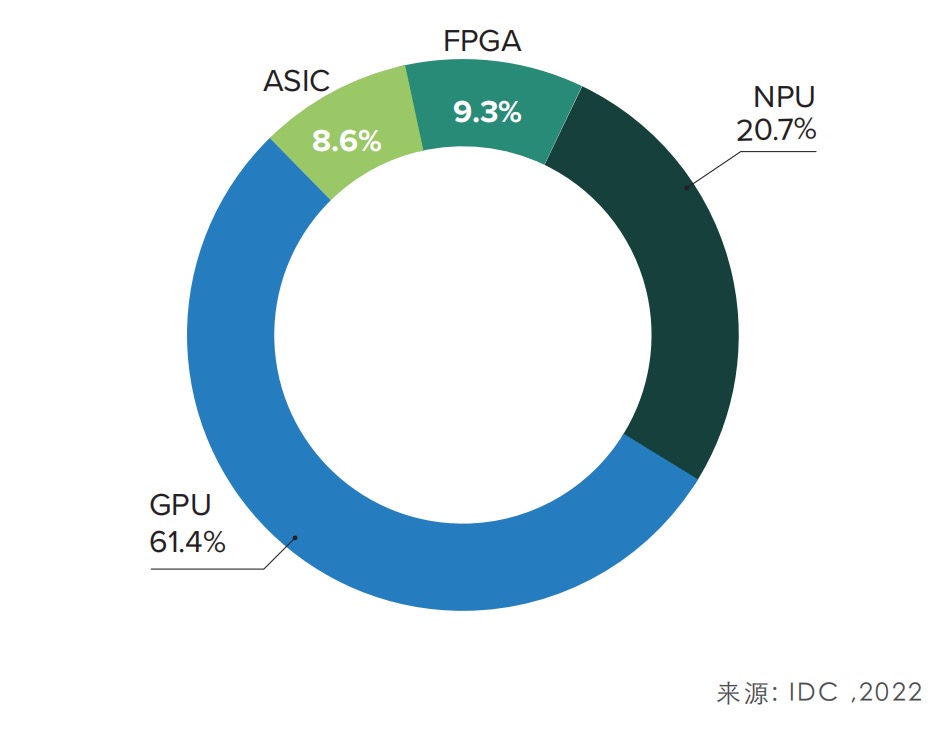
结合IDC的报告,通用GPU已成为数据中心底层硬件的首选,份额高达61.4%。同时汽车行业训练自动驾驶算法的硬件基础设施也基本以GPU为主。包括特斯拉、蔚来、小鹏等都选择了英伟达的GPU产品。
根本原因在于,自动驾驶算法的发展需要借助深度神经网络在高速状态下分析海量数据,而这恰恰可以利用GPU在处理琐碎信息时的优势。
作为并行计算的开拓者,英伟达 GPU在AI服务器市场的占有率约为60%~70%,远超老对手AMD和英特尔。财通证券预测,大语言模型有望持续拉动GPU需求量,2023/2024/2025年大模型有望贡献GPU市场增量69.88/166.2/209.95亿美元。
英伟达是人工智能时代的最大赢家吗?虽然不能就此断论,但在大趋势面前,它的确是被时代塑造的“巨无霸”。
人工智能计算中心硬件基础设施
云端/边缘通用GPU,谁执牛耳?
不过,黄仁勋也有自己的担忧。
近期,他在接受《金融时报》《日本经济新闻》等多家主流媒体采访时一直强调,美国对华芯片出口管制措施将造成严重影响。
英伟达约有21%的收入来自中国大陆,相比博通、高通等美国公司,这个数字不算起眼,但黄仁勋直言,这项禁令让英伟达“双手被反绑”。中国大陆约占美国科技业市场的三分之一,如果双边无法正常贸易,美国公司无疑首当其冲。
更重要的是,这些公司既要砍产能,又可能面临芯片供过于求、业绩衰减、竞争力下滑的风险。
去年8月,美国政府发布了一项新禁令,要求英伟达不得对中国大陆(含香港)出口已经商用的A100和即将推出的H100系列产品,引发市场哗然。
不过随后,华盛顿给予了英伟达A100半年的缓冲期,在2023年3月1日前,开放英伟达出口美国客户的A100芯片订单到中国大陆。同时,批准其在2023年9月1日前,通过香港子公司供应GPU芯片。
这之后,就有了国内云服务提供商、科技公司和自动驾驶公司纷纷囤积GPU的故事。
尽管英伟达后续推出了符合出口标准的“特供版”GPU——A800和H800,但地缘政治风险就像悬在头顶的达摩克利斯之剑,不知道什么时候就会落下。
黄仁勋在Computex圆桌会议上也表示,无论(美国)新规是什么,英伟达都会绝对遵守。但他也称,中国大陆会利用这个机会培育本土产业。
他举了一个例子,“如果你本身不在芯片行业,但想创办一家公司,你会成立什么公司?——你会成立一家GPU企业。”毫无疑问,AI催生的大量需求和高端GPU的限售,给了国产GPU巨大的替代空间。
GPU的发展路径主要有两条,传统的图形渲染和聚焦高性能计算的通用GPU。应用则面向云端和边缘两大领域。近年来,国内涌现出了大批GPU公司,都拿出了较为成熟的产品和技术。在通用GPU领域,不乏有正面挑战英伟达在云端数据中心地位的。
“我们必须跑得非常快,中国目前投入到芯片领域的资源十分庞大,我们不能低估他们(这些公司)。”这是黄仁勋的最新发言。
在此,盖世汽车也整理了国内几家做通用GPU的公司,名单及相关产品如下:
1.寒武纪:

2022年3月21日发布新款训练加速卡MLU370-X8,搭载双芯片四芯粒思元370,集成寒武纪MLU-link多芯互联技术,主要面向训练任务,在业界应用广泛的YOLOv3、Transformer等训练任务中, 8卡计算系统的并行性能平均达到350W RTX GPU的155%。
2.壁仞科技:

2022年8月9日发布首款通用GPU芯片BR100,采用7nm工艺,集成770亿晶体管,使用Chiplet技术,2.5D CoWos封装技术,芯片面积达到1000平方毫米。算力创下全球纪录,16位浮点算力达到1000T以上、8位定点算力达到2000T以上,单芯片峰值算力达到PFLOPS级别。
该公司现已加入中国移动算力网络“芯合”新型智算开放实验室,并成为中国电信“云网基础设施安全国家工程研究中心云计算合作伙伴”。
3.燧原科技:

2021年7月7日,燧原科技推出第二代人工智能训练产品——“邃思2.0”芯片、基于邃思2.0的“云燧T20”训练加速卡和“云燧T21”训练OAM模组。并先后与上海国际汽车城、云豹智能、达观数据等建立合作关系,打造计算平台。
4.天数智芯:

2022年12月21日,天数智芯正式推出了通用GPU推理产品“智铠100”。该芯片支持FP32、FP16、INT8等多精度混合计算,实现了指令集增强、算力密度提升、计算存储再平衡,支持多种视频规格解码。而智铠100产品卡,可以提供最高384TOPS@int8、96TFlops@FP16、24TFlops@FP32的峰值算力,800GB/s的理论峰值带宽以及128路并发的多种视频规格解码能力。截至目前,该公司已与云创大数据等公司就AI大模型达成合作。
5.摩尔线程:

2022年11月3日,摩尔线程推出了基于自研架构MUSA的第二颗多功能GPU芯片“春晓”,以及基于春晓打造的面向服务器的GPU产品MTT S3000。
MTT S3000支持DirectX、OpenGL、OpenGL ES、Vulkan、OpenCL等主流图形和计算接口,兼容CUDA,可为AI推理和训练、云游戏、云渲染、视频云、数字孪生、数字内容创作等场景提供通用智能算力支持,旨在为数据中心、智算中心和元计算中心的建设构建坚实算力基础,助力元宇宙多元应用创新和落地。
除了以上公司,国内还有景嘉微、沐曦等知名GPU企业,以及一批借着人工智能革命飞快成长的GPU初创。在产品应用和平台生态建设方面,国内GPU企业不比英伟达等海外巨头,但就像黄仁勋自己说的,第一波AI应用热潮在云端大语言模型上,而下一波则在企业端。电竞游戏、元宇宙、自动驾驶都可能是未来通用GPU的风口。
英伟达赢在了上半场,但下半场,谁又能杀出重围,尚未可知。 即便遍地是黄金,即便强如英伟达,也绝对不能松懈。